AI Agent Best Practices: Trust Your Own Results Before Google
Knowledge is not flat. It has an address book, and the closest door comes first.
What ran and worked in your environment beats what you wrote down. What you wrote down beats what a teammate remembers. What a teammate remembers beats the top search result. The open web is the last door you knock on, not the first.
Most setups have this inverted. The agent reaches for its web search tool first and treats your own proven work as an afterthought. You hired a senior and pointed it at Stack Overflow.
The fix is not smarter prompts. It is a trust order the agent actually follows.
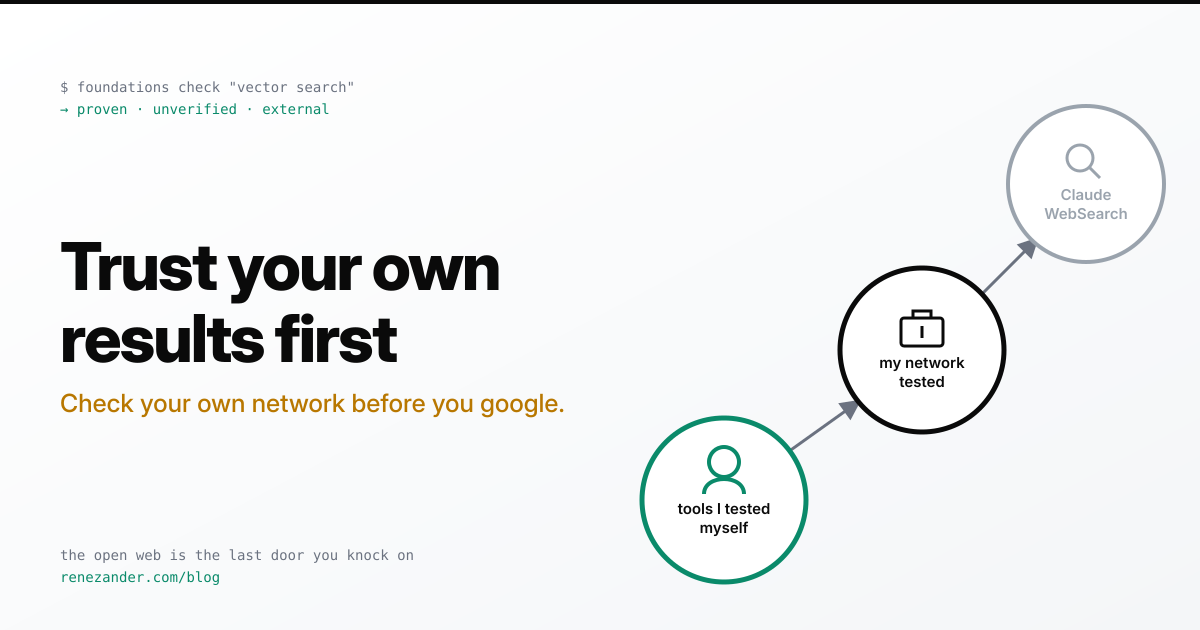
Your agent trusts Claude’s web search tool more than the fix you proved worked last week. Not because the tool is wrong. Because you never told it where to look first.
Watch it set up a cron job, pick a vector store, write a retry. It reaches for the generic best practice, the one from a tutorial written for nobody in particular. The battle-tested version, the one that survived your own 3am incident, sits unread in your own repo.
That is the bug. Not the model. The order.
The Best Practice You Googled Is Frozen
A best practice on the open web is someone else’s debugging session, frozen and stripped of the context that made it true. It worked once, on a setup that is not yours. Your own proven result already survived your environment, your data, your load. One is a recipe. The other is a dish you have already cooked.
This is the part the current advice gets backwards.
Context quality predicts output quality better than your prompt does. A study of nearly ten thousand runs landed on it.
And the most common reason AI coding stalls on a team is context fragmentation. Knowledge that exists, scattered, with no order.
So the reflex is to pour more best practices into the CLAUDE.md. More rules. Louder.
That is more frozen recipes in a bigger drawer. It does not fix the order. It buries it.
Five Moves, No Special Tooling
You do not need my setup to get the order right. You need these five.
- Write your proven results down. The fix that survived an incident becomes a one-line note your agent can read. A win you cannot retrieve is a win you will google again.
- Give your context file a trust order, not rules alone. Mark what is proven versus what is a guess. The agent treats them differently because they are different.
- Make it check your own work before it researches. One command at the top of the loop. Own results first, web only when that comes up empty.
- Rank your sources out loud. Ran-and-worked, then your notes, then a teammate, then the open web. Label the last one untrusted until you validate it.
- Ask your inner circle before the crowd. The person who solved your exact problem outranks the top result. Reach for them first.
The Inner Circle Is a Graph
Recommending a best practice is a graph problem. Not text similarity, trust proximity. The people and repos closest to you, who solved your exact problem, ranked ahead of the loudest stranger. Inner circle first, then the next ring, then the open web.
Your agent already walks a graph every time it retrieves. Right now it ranks by what reads similar. The upgrade is ranking by what you have reason to trust.
Proven results are a graph you already own. You have not told the agent to walk it yet.
So look at your own loop. When your agent needs an answer, which door does it knock on first?
I run this sweep at the top of mine, as a check before any research.
Fixed price and milestones — or a clear no with reasons.
Running an AI pilot that is not production-ready yet? That is exactly what I do: audit, fixed-price scope, delivery in 2–6 weeks.