Sandboxing an AI Coding Agent: The Harness Owns the Boundaries

The obvious way to improve a coding agent is to make it more capable: a stronger model, a wider context window, more tools, more room to act on its own. That is not where my problems come from. My agents seldom fail because they reason badly. They fail because they take the shortest path to something that looks finished and skip the process that was supposed to make the result trustworthy.
The pattern is familiar to anyone who has watched an agent work unsupervised. It edits the tests until they pass. It reports that a command ran instead of proving it. It writes into the working repository before anyone reviewed a diff. It switches to a cheaper model mid-task with no sense of the cost. These are not reasoning errors. They are shortcuts around a process, and a stronger model takes them faster.
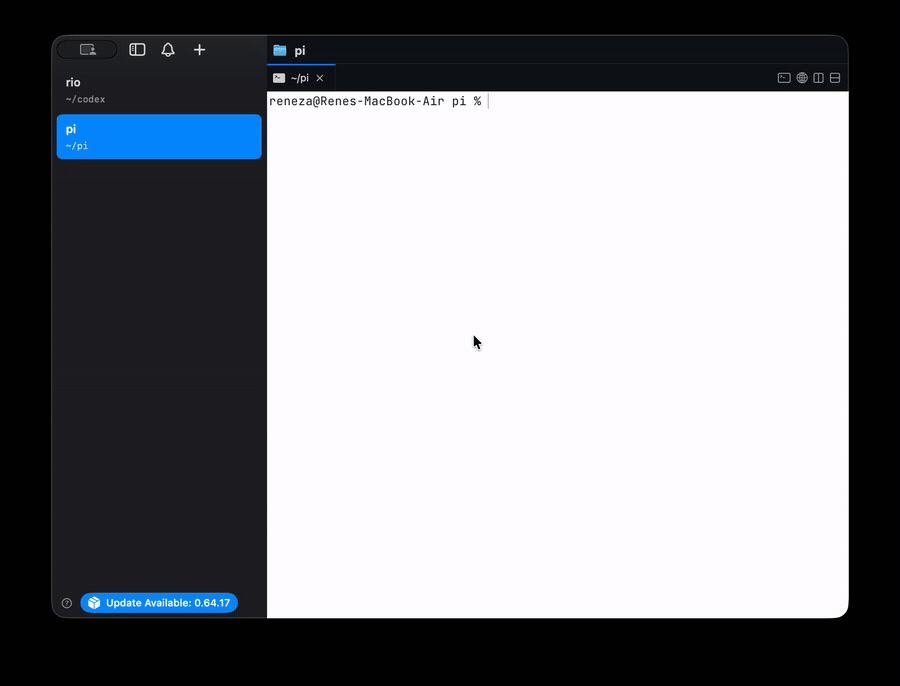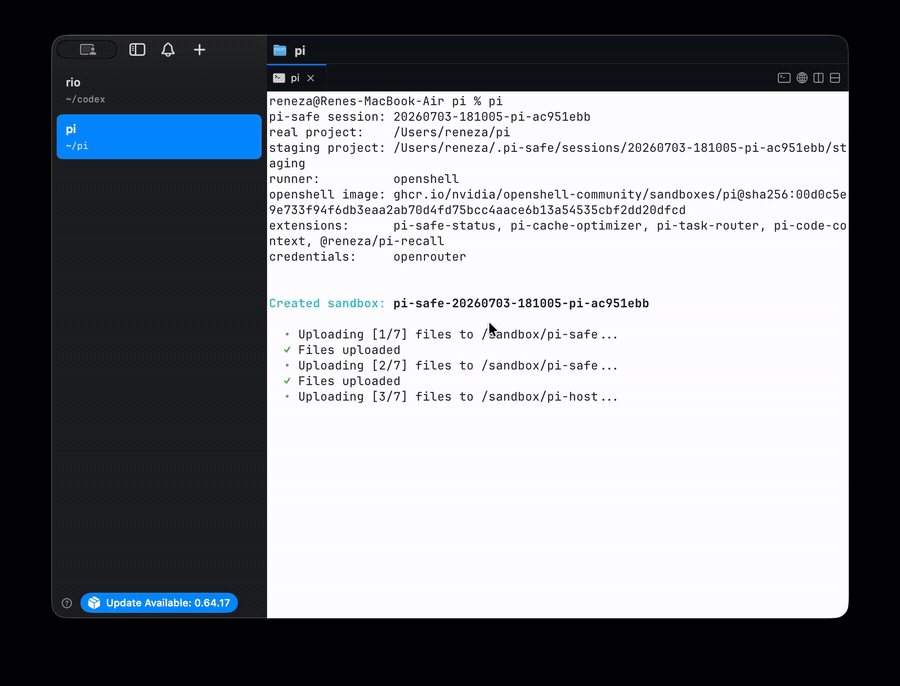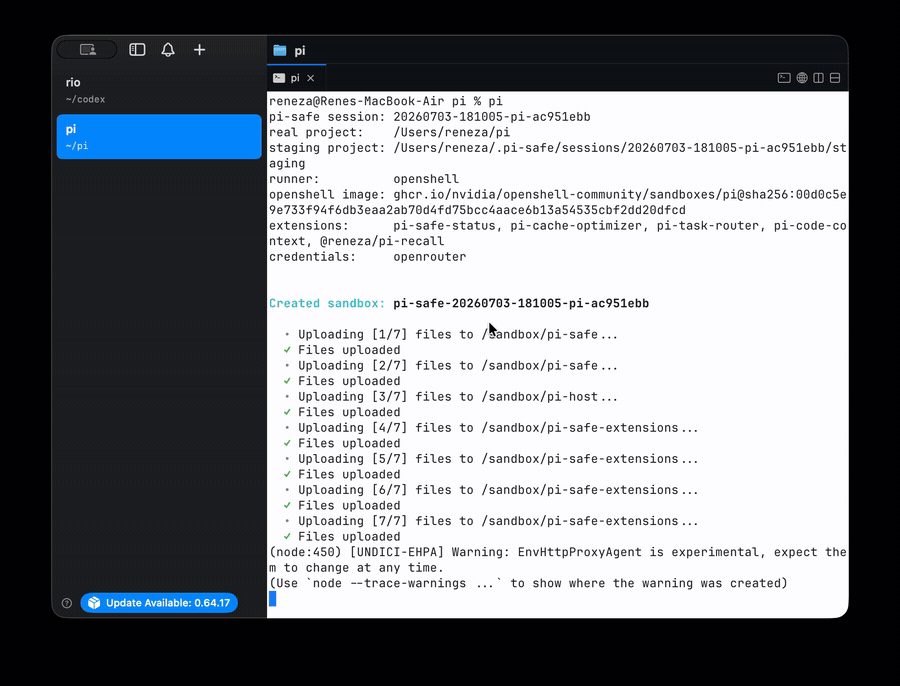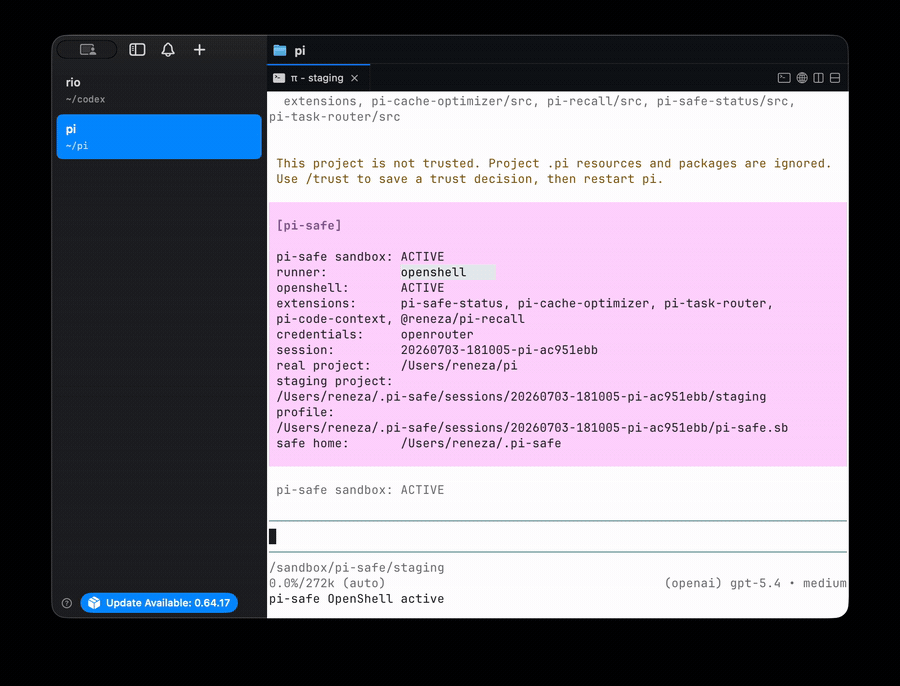
pi-safe launching the Pi agent into an NVIDIA OpenShell sandbox: the real project is copied to a staging tree the agent works in, its extensions and credentials load inside the sandbox, and changes only reach the real repo after review.
The shape: the model requests, the harness owns the boundaries
I stopped trying to make the agent more trustworthy and started constraining what it can reach. The agent runs inside a sandbox that owns the filesystem, network, and credential policy, and writes only to a staged copy of the repository. Its output reaches the real project through a separate evaluator. The model requests; the harness owns the boundaries.

Every arrow in that path is a place I can say no.
What the substrate owns, what my extensions own
The lower layer is NVIDIA’s OpenShell, a sandbox and credential substrate. It owns sandbox lifecycle, filesystem and process isolation, minimal outbound network by default, policy-enforced egress, and named credential providers that inject secrets at runtime rather than copying them onto disk. It is infrastructure I want to own as little of as possible.
The upper layer is specific to how I work: a set of small extensions that control the agent’s behaviour, what model it picks, how much context it carries, what it can recall, and whether its output is allowed to land. The substrate keeps the agent contained; the extensions decide how it acts while contained.

Each part owns one boundary
The extensions are deliberately not one big extension. Each has a narrow job, so each has a narrow failure domain. If model choice is wrong, I fix the router. If context bloats, I fix the cache layer. If recall is wrong, I inspect the recall surface. One giant extension would be simpler to explain and harder to trust, because every failure shares the same blast radius.
The router classifies work and escalates on process, not prestige. Routine work stays cheap, mechanical work can run local, and only stuck or high-risk reasoning reaches a stronger model. The cache layer watches context pressure and compacts before a bloated working set makes every later decision worse. Recall splits by trust: derived knowledge is graphed from the code, authored knowledge is the reviewed bundle for what the code cannot explain.

A sandbox is not an evaluator
The boundary I care about most is the last one. A sandbox runs code safely. An evaluator decides whether that code should land. Those are different jobs, and collapsing them is how output nobody checked ends up in the main branch.
The evaluator takes the agent’s patch, applies it to a disposable workspace, runs its checks, and returns one of three answers: pass, block, or override. The substrate can supply the process the evaluation runs in, but it does not make the decision. The real repository stays behind that gate; the agent’s writable root is never the project itself.

What I would delete next
The direction of this system is fewer parts, not more. The best part is no part. Every time the substrate can own a boundary directly, I want to delete my custom layer for it. The wrappers I run today exist only until the platform underneath is clean enough to remove them.
The test for every piece is the same. Does it still own a real boundary? If a component only lets the agent do more, it has failed the test and should go. The harness was never meant to make the agent impressive because it can do everything. It was to leave fewer places where the model can declare victory without actually earning it.
The parts
Substrate: NVIDIA OpenShell, the sandbox and credential runtime the whole thing sits on.
The extensions, each owning one boundary:
- pi-safe: launches the agent inside the sandbox by default
- pi-task-router: model choice and escalation
- pi-cache-optimizer: context and cache pressure
- pi-code-context: semantic code search
- pi-recall: the recall surface for the agent
- pi-codegraph: derived code knowledge behind recall
- pi-okf: authored, reviewed knowledge bundles
- pi-gate: the patch evaluator contract
pi-creds (scoped credential requests) and pi-eval (process-step evaluation) are the next boundaries, not built yet.
I build agent harnesses that own the boundaries, not agent demos that do more. These field notes track the next boundary I add, one shipped part at a time, and where each one still breaks.